(Hopefully, This Will Help Contextualize the Homework)
Node?
Hmmmm. For a class on Node, we haven't really talked about it too much yet. Does anyone know what Node.js is exactly? →
- a JavaScript server side and networking framework
- like JavaScript on the browser, minus the DOM/HTML stuff
- but… with more I/O and networking support added in
- designed to maximize throughput and efficiency through non-blocking I/O and asynchronous events
- some technical details:
- it's built on top of V8 (Chrome's JavaScript engine)
- it's written in C, C++, and JavaScript
In Node, All I/O is Non-Blocking and Asynchronous
Hold on … I/O?
What exactly do we mean by I/O →
- reading or writing to a database
- requesting data from a web service
- scanning through a file
- waiting for some network connection
- you know… any input and output
What does blocking I/O look like?
Using Python and the requests module, it may look something like this. What do you think the following code would print out? →
import requests
print('Start')
response = requests.get('http://www.google.com')
# just print out the first 30 characters of the response body
print(response.text[0:30])
print('Done!')
Start
<!doctype html><html itemscope
End
And non-blocking I/O
This example uses a Node.js library called Request (as well!). What does this output? →
var request = require('request');
console.log("Start");
request('http://www.google.com', function (error, response, body) {
// just print out the first 30 characters of the response body
console.log(body.slice(0, 30))
})
console.log("Done!");
Start
Done!
<!doctype html><html itemscope
Weird, Huh?
Why was "Done" output before the response body? →
- the function to print out the body was actually an asynchonous callback
- a callback is a function passed as an argument to another function that is expected to be executed at some later time (perhaps when an operation is completed, or a specific event occurs)
- the callback function is not executed immediately
- instead,
console.log("Done!")is executed next - when the request to google is done, the callback function is executed, which is at the end of the program
(Other languages have asynchronous, event-driven frameworks as well, including Twisted for Python and Eventmachine for Ruby)
Some More Details
- Node applications (your actual JavaScript code) are actually a single process
- but all I/O operations are non-blocking and happen in the background
- this is done through an event loop
- Node just continues to listen for events
- you specify what code to execute whenever an event happens
- if something requires I/O, that's spun off in the background, so the event loop can handle other callbacks
- this is all based on the assumption that I/O is the most expensive operation, so why wait for it when you can move on to other code to execute?
- your node app can still block, though (even if I/O is asynchronous)… how? →
- if your code is computationally heavy!
"Everything runs in parallel, except your code"
Aaaand More Details
Even more about single-threaded, but non-blocking in Node
A challenge with callbacks is that it may be difficult to acquire the context of the original function that spawned the callback. With JavaScript, though, it's easy! Why?
- quoted from the SO post above
- "Every function that requests IO has a signature like function (… parameters …, callback)" and needs to be given a callback that will be invoked when the requested operation is completed
- "Javascript's support for closures allows you to use variables you've defined in the outer (calling) function inside the body of the callback - this allows to keep state between different functions that will be invoked by the node runtime independently"
Node Works Because of JavaScript's Language Features!
OK, Got It…
So… When should you used Node?
- I/O bound workloads (not so much for CPU bound!)
- when you don't want to deal with the complexities of concurrent programming, and your application can fit into an event-driven framework
Some actual examples
- for web stuff…
- like high traffic APIs
- soft real time apps
A Bunch of Parentheses
- (not sure if a console-game was a great use-case…)
- (waiting for user input can be considered an I/O bound app, though!)
- (but we used a synchronous prompt library to gather input)
- (you can rewrite with another lib if you want!)
Using Node
(This is obvs, I know, but just for completeness). After you've installed via your apt/homebrew/download, you can run node in two ways:
- as a REPL / interactive shell, which is just:
node(CTRL-D exits) - or to execute a program:
node filename.js
Of course, you can write vanilla Node programs using whatever's built in, but you'll probably some libraries
NPM
NPM is Node's official package manager. Does anyone know of any other package managers for other languages? →
- gem for Ruby
- or pip, easy_install for Python
- or CPAN for Perl
- or composer for PHP
Among other things, npm allows you to download and install packages (modules), as well as remove and upgrade them.
Installing Packages
npm install packagename
- by default, NPM installs packages in a directory called
node_modulesin the directory that you run it in- let's see that in action →
- which is why you should
.gitignorenode_modules(you don't really want all of the dependencies in your repository)
- that means NPM doesn't install globally by default (nice… unlike other package management systems)
Local vs Global Installation
You can use the -g flag to install globally if you need to (and it will be necessary for some things): npm install packagename -g
- some libraries are actually commandline tools that you want to use throughout your system - install these globally
- while others are libraries for specific apps that you're developing (anything that you'd
requirein your program) should be installed locally
More About Global Package Installation
Why do we want to avoid installing modules globally? →
- multiple apps, different dependencies
- maybe even OS level dependencies!
BTW, what are some analogous tools that we'd use to avoid installing packages globally for python and ruby? →
- rvm
- virtualenv
package.json
Lastly NPM can use a file called package.json to store dependencies. This will usually be placed in the root of your project folder.
Other languages specify dependencies in specific files too:
- gemfile - ruby
- requirements.txt - python
Soooo… if your program depends on a set of modules
- it may be a good idea to put that module in package.json
- … so that you don't have to remember all of the requirements, and they can be installed all at once!
package.json Continued
A sample package.json for a tic-tac-toe game that requires:
- synchronous (blocking) i/o for asking for console input (readline-sync)
- assertions for unit tests (chai)
May look like this:
{
"name": "tic-tac-toe",
"version": "1.0.0",
"dependencies": {
"readline-sync": "^1.4.4"
},
"devDependencies": {
"chai": "^3.5.0"
},
}
Modules
So… what is npm installing? What are these modules anyway?
Modules are just JavaScript files!
- you can bring in the code from one file into another file using the
requirefunction - however, your module must explicitly export the objects/functions that can be used by the file that's bringing in the module
- there are built-in modules
- …and you can, of course, write your own modules!
A Little More Than Just Files
From the node docs on modules:
Before a module's code is executed, Node.js will wrap it with a function wrapper that looks like the following:
(function (exports, require, module, __filename, __dirname) {
// Your module code actually lives in here
});
- which keeps top level variables scoped to the module than global (so when you require a module, it doesn't pollute your global name space!)It helps to provide some global-looking variables that are actually specific to the module, such as:
- the module and exports objects can be used to define what's accessible by the file bringing in the module
- convenience variables: __filename and __dirname, the module's absolute filename and path
Using exports
- Create all of your functions …
- Then, at the end, assign module.exports to an object literal containing all of the functions that you want to export
function repeat(ele, n) {
// implementation
}
function generateBoard(rows, cols, initialValue) {
// implementation
}
// ...
module.exports = {
repeat: repeat,
generateBoard: generateBoard,
// ...
}
Another Way
Create all of your functions in an object and assign that object to module.exports →
var tic = {
repeat: function(value, n) {
// implementation
},
generateBoard: function(rows, columns, initialCellValue) {
// implementation
},
// ...
}
module.exports = tic;
Note that if one function depends on another, you'll have to prefix with the object name (module.exports or this.
Aaaaand…
Create functions as properties on module.exports →
module.exports.repeat = function(value, n) {
// implementation
}
module.exports.generateBoard = function(rows, columns, initialCellValue) {
// implementation
},
// ...
Note that if one function depends on another, you'll have to prefix with the object name (module.exports or this.
Node.js - require
Node's built-in function require is analogous to:
- PHP's include
- Ruby's require
- Python's import
- Java's import
It returns an object… and that object most likely has some useful methods and properties. From our request example earlier:
var request = require('request');
Modules Continued
Again, modules allow the inclusion of other JavaScript files into your application. From the Node docs:
Files and modules are in one-to-one correspondence
In other words, modules are just JavaScript files. The Node docs are pretty comprehensive about how modules work.
Core Modules
Some modules are compiled directly into the node binary. They're available without having to create or download a module. A couple of useful core modules include: →
- HTTP - for creating both HTTP clients and servers
- File System - for manipulating files and directories
Require in Detail
Using a module:
- the
requirefunction loads a file- it takes a single argument, the name of the file to load (the .js extension can optionally be omitted when loading)
- it gives back an object
- …the object that it returns has all of the exported properties of the module / file loaded
- let's try it out with a core module →
// bring in the http module
var http = require('http');
Downloaded Modules
Of course, we're not stuck with just using the core modules. We could download pre-built modules as well. How did we install some Node modules and how did we use them? →
npm install module-name
var prompt = require('readline-sync').prompt;
var request = require('request');
Creating your own module:
- there's an available
exportsobject in Node - creating properties on that object makes those properties public to whatever is importing the file
- variables that aren't exported are private to the module
- lets take a look (notice that the
exportsobject is not available in the shell) →
// showing what's in exports
console.log(exports);
// adding a property to exports
exports.foo = 'bar, baz';
All Together
Here's a full example of creating and using a module: →
A module called creatures.js:
exports.makeCreatureList = function (r) {
return ['narwhale', 'unicorn'];
};
And… using that module: →
var creaturesModule = require('./creatures.js');
creaturesModule.makeCreatureList().forEach(function(name) {
console.log(name);
});
Module Location
Where do you think the require function looks for a module? (we can probably guess 3 places correctly!) →
Some hints:
- installing modules for homework
- consider the examples in the previous slides
- if it's a core module, just bring the module in (it's compiled into the node binary)
- if it's a file (starts with /, ../, ./, etc.),
- try to find that file relative to the location of the file that has the call to require
- or as an absolute path
- or load it from the node_modules folder (which is where modules are downloaded when you install from npm)
Or… just check out the crazy docs.
Notes About Downloading and Installing Modules
- modules are downloaded and installed in the node_modules directory located in in the directory that you ran npm
- if it's not found there, it will look at the parent's directory's node_modules folder
- it will continue to look one directory up until the node_modules (if it exists) directory at the root of the filesystem is reached
- be careful with regards to where things are installed / moving projects around
You should place your dependencies locally in node_modules folders
Why Modules?
Why do modules exist? Why is certain functionality broken out into modules? Why would we create our own modules?
- modules provide solutions to commonly encountered programming tasks
- they promote code reuse
- namespacing and preventing naming collisions
- organizing code / keeping related functionality together
Node's Module System
JavaScript, the language, doesn't actually have a module system!
Node's module system is built off of a spec/API called CommonJS.
You won't be able to use this same module system in browser implementations of JavaScript without first including other JavaScript files/libraries (and there are a few to choose from) manually on your page.
Debugging
Let's Write a Quick Function
Create a function that determines if a set of parentheses is balanced (what does that mean?): →
- name: isBalanced
- signature: isBalanced(string) → boolean
- parameters: a string (assume that it only consists of "(" and ")")
- returns: true if the parentheses are balanced, false if they aren't
- a set of parentheses are balanced if there's exactly one closing parentheses for each open parentheses
- why wouldn't comparing counts work? →
)(- one algorithm is to push open parentheses when you see them, but pop them when you see closed parentheses
Here's an Implementation
var isBalanced = function(s) {
var stack = [], balanced = true;
for(var i = 0; i < s.length; i++) {
var ch = s.charAt(i);
if (ch === '(') {
stack.push(ch);
} else if (ch === ')') {
if (stack.length === 0) {
balanced = false;
break;
}
stack.pop();
}
}
if (stack.length !== 0) {
balanced = false;
}
return balanced;
};
Testing It
console.log(isBalanced('()'));
console.log(isBalanced(')('));
console.log(isBalanced('()()'));
console.log(isBalanced('()())'));
Let's Check Out Some Debugging Tools…
Let's intentionally create a logical error in our code (perhaps return immediately after popping). To figure out what went wrong, we can… →
- just print stuff out with console.log (the old fashioned way!)
- use a debugger
The Commandline Debugger
node debug myscript.js
Let's give this a whirl…
Wait… what? The commandline is hard. Let's go shopping
Terrible. Yay 90's. Though the "elaborate nationwide publicity stunt designed to ridicule sexual stereotyping in children's toys" was pretty neat!
Don't Worry, There Are Other Debugging Tools Out There
- Sublime Web Inspector (for Sublime, of Course)
- WebStorm a commercial JavaScript IDE (what a spectacular name, though)
- Node Inspector - just like Chrome's Web Inspector!
I'm partial to Web Inspector because it's IDE agnostic, and as you know, as an old person vintage editor enthusiast, I use vim.
Fail Live Demo Time
Node Inspector
- install node-inspector:
sudo npm install -g node-inspector - (hey did you notice that it's global… why →)
- run node-inspector:
node-inspector - open another terminal window…
- start your app, the –debug-brk option will pause on the first line:
node --debug-brk app.js - open Chrome and go to http://localhost:8080/debug?port=5858
Node Inspector Continued
Same as Chrome Web Inspector! See the docs!
Like any other debugger, you can:
- continue
- step over
- step in
- step out
- watch (check out the variables in the closure even!)
- set breakpoints
- have. lots. of. fun.
Great. Wrote Some Code. Let's Put it in Version Control.
Version Control (With Git)
The material in these slides was sourced from:
Um. First… Archiving?
What are some ways you've used to keep / save different versions of files? →
- adding a date to a file name?
- adding extensions to files, like .bak?
- organizing copies by folders?
- …perhaps folders with timestamps / dates
- ummm… etc.
What are some drawbacks of these methods of saving versions of files? →
- it's all manual
- … and, consequently, tedious and error prone
Sharing / Collaborating
Have you ever worked on a programming project with more than one person? How did you share your code? →
- email?
- usb?
- dropbox?
What are some issues with these methods (well, except for dropbox)?
- hard to find a specific version
- which one is the latest?
- how do you deal with conflicting changes?
Enter: Version Control
What's Version Control?
Version control software allows you to record changes to a file or set of files over time so that you can inspect or even revert to specific versions.
- can be applied to any kind of file, but we're mostly using text files
- with version control, you can:
- leave comments on changes that you've made
- revert files to a previous state
- review changes made over time, and track who made them
- you can easily recover from accidentally breaking or deleting code
- automatically merge changes to the same file
So… Um. Why?
Version control can help us:
- stop using .bak files!
- collaborate with others
- share our code
- merge changes from different sources
- document our work
- group related changes
Oh. And it's kind of expected that you know this as a professional programmer.
We’re Using git!
- git is the version control system that we're using
- it’s a modern distributed version control system
- it has emerged as the standard version control system to use
- (some others are…)
- mercurial
- subversion (svn)
- cvs
A Bit About Git
It was developed by Linus Torvalds… who? →

(the guy who made Linux)
What a nice person!
Github vs git
GIT AND GITHUB ARE DIFFERENT!
- github is a website that hosts git repositories
- on it's own, git is just version control
Who Uses Git and Github?
Git is used to maintain a variety of projects, like:
- the Processing IDE
- or Twitter's Bootstrap
- or Ruby on Rails
Some people use github to distribute open source code… for example:
- id software has a bunch of stuff hosted on git
Local Version Control
- equivalent to what we may have done manually:
- save files in folder with locally as a snapshot of current state of code
- recover by going through folders on computer
- see versions by the timestamped folder name
- all of this is automated through software
- stores changes to your files in a local database
- an example of local version control is RCS
Centralized Version Control
- promoted collaboration; everyone got code from the same place
- single server that has all of the versioned files
- everyone working on it had a working copy, but not the full repository
- an example is subversion (SVN)
Distributed Version Control
- everyone has full repository
- can connect to multiple remote repositories
- can push and pull to individuals, not just shared or centralized servers
- single server that has all of the versioned files
- everyone working on it had a working copy
We're Using Git, a Distributed Version Control System
(But We're Really Going to Use a Central Repository Anyway)
A Quote…
From a co-worker of mine, a software engineer that builds web apps:
"Git is the hardest thing we do here"
(it's a little complicated, but not for what we're using it for)
Some Terminology
repository - the place where your version control system stores the snapshots that you save
- think of it as the place where you store all previous/saved versions of your files
- this could be:
- local - on your computer
- remote - a copy of versions of your files on another computer
Some More Terminology
- git - the distributed version control system that we're using
- github - a website that can serve as a remote repository for your project
What's a remote repository again? →
A copy of versions of your files on another computer/server
Where Are My Files
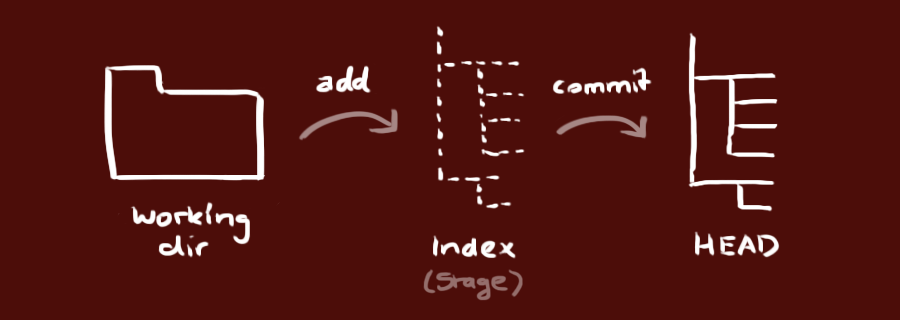
In your local repository, git stores your files and versions of your files in a few different conceptual places:
- the working directory / working copy - stores the version of the files that you're currently modifying / working on
- index - the staging area where you put stuff that you want to save (or… that you're about to commit)
- HEAD - the most recent saved version of your files (or… the last commit that you made)
Another Way to Look at It
- the working directory / working copy - stuff you've changed but haven't saved
- index - stuff that you're about to save
- HEAD - stuff that you've saved
Aaaaand. More Terminology.
- commit - save a snapshot of your work
- diff - the line-by-line difference between two files or sets of files
Two Basic Workflows
- Creating and setting up local and remote repositories
- Making, saving, and sharing changes
Creating Repositories
- create a local repository
- configure it to use your name and email (for tracking purposes)
- create a remote repository
- link the two
Making, Saving, and Sharing Changes
- make changes
- put them aside so they can staged for saving / committing
- save / commit
- send changes from local repository to remote repository
Ok. Great!
Remind me again, what's github? →
- github is a website
- it can serve as a remote git repository
- that means it can store all versions of your files
- (after you've sent changes to it)
We can now submit assignments using the commandline
(Um. Yay?)
Creating and Setting Up Repositories
Commands for Creation and Set Up of Repositories
We'll be using this for most of our work…
git clone REPO_URL
This stuff, not so much, but you should know them too…
git initgit config ...git config user.name "__your user name__"git config user.email __your@email.address__
git remote add REMOTE_NAME REMOTE_URL
git clone
Again, for most of our work, you'll just be cloning an existing repository (creating a local repository from a remote one).
git clone REPOSITORY_URL
REPOSITORY_URL is usually going to be something that you copy from github.
git init
git init - creates a new local repository (using the files in the existing directory)
- you can tell a repository is created by running ls -l … it creates a .git directory
- again, this creates a new repository - a place to archive / save all versions of your files
# in the directory of your repository
git init
git config
git config - configure your user name and email for your commits
- this has nothing to do with your computer's account or your account on github
- this information helps track changes
# in the directory of your repository
git config user.name "foo bar baz"
git config user.email foo@bar.baz
git remote add
git remote add - add a remote repository so that you can synchronize changes between it and your local repository
git remote add REPOSITORY_NAME REPOSITORY_URL
Typical Workflow for Making Changes
- make changes
- git status (to see what changes there are)
- git add –all (to stage your changes for committing)
- git status (to see your staged changes)
- git commit -m 'my message' (to save your changes)
- git push origin master (optionally send/share your changes to a remote repository)
Check out a workflow chart here: http://rogerdudler.github.io/git-guide/img/trees.png
{kind=link}
git status
git status - show what changes are ready to be committed as well as changes that you are working on in your working directory that haven't been staged yet
git status
git add
git add - mark a change to be staged
# in the directory of your repository
# add all
git add --all
# add specific file
git add myfile.txt
git commit
git commit - take a snapshot of your work
# in the directory of your repository
# don't forget the commit message
git commit -m 'commit message goes here'
git log
git log - show commit history of your repository or file
# in the directory of your repository
git log
#you can also colorize the output:
git log --color
git diff
git diff - show the line-by-line differences between your last commit and your working directory
# in the directory of your repository
# use --color for syntax highlighting
git diff --color
git reset
git reset - revert last commit… or unstage changes
# unstage changes
git reset filename.txt
# revert last commit
git reset HEAD^
git push
git push - send your code to a remote repository
git push
# or to specify... push master branch to remote
# repository called origin
git push origin master
OK… how about getting all of this set up for our assignment?
Regarding Submission
Again, I will clone all of the repositories at the homework's deadline. That means… →
- any commits made after the deadline…
- won't be seen by the graders
Details Again…
(they may not have made sense at the beginning of class… but maybe now?)
- if git clone doesn't work, use init workflow
- name the files and function exactly as specified
- commandline arguments:
process.argv[2]